Progress
I got an email #
I got an email from some Internet aquaintances whose newsletter I subscribed to some years ago. This newsletter is the one immediately following the 2024 U.S. election, and they have a podcast link to a friendly and rational discussion of the recent events.
I get ready to click on the link. The link is this:
https://ctrk.klclick.com/l/01JC6N4DXHQTS1X5DZEZTGB7RP_1
I've been on the Internet long enough to know what a tracking URL looks like.
This one is kind enough to even say what it's doing on its tin (trk being
'track'). But even if it was less obvious, the URL doesn't really look like
something that could be a podcast or podcast service, so that's usually a clue
that something else is going on.
I'm also enough of a computer person to know that the
01JC6N4DXHQTS1X5DZEZTGB7RP_1 in the URL is a unique identifier. If I look at
the other links in the email I see that each link has its own unique identifier.
Likely, these are just unique identifiers for each URL so that the klclick.com
tracker can redirect you to the proper link after you click. But they can also
be unique to every newsletter recipient. It's one thing to know how many people
clicked on something in your newsletter. It's something else entirely if you
know that Josh, in particular, clicked on something in your newsletter.
I'm not overly fond of having my activities tracked across the Internet. But still. I trust the senders. I know that they are just two people, and that they run a business, and that they need this sort of information to be responsive and competitive. In fact, they've got their own podcast where they talk about things like whether their newsletter 'opt-in' checkbox should be checked or unchecked. They certainly know about and think about these things a lot, and would know the difference between malicious tracking and not. And what's the harm in a little bit of tracking between Internet aquaintances?
So I click.
Firefox gives me this:
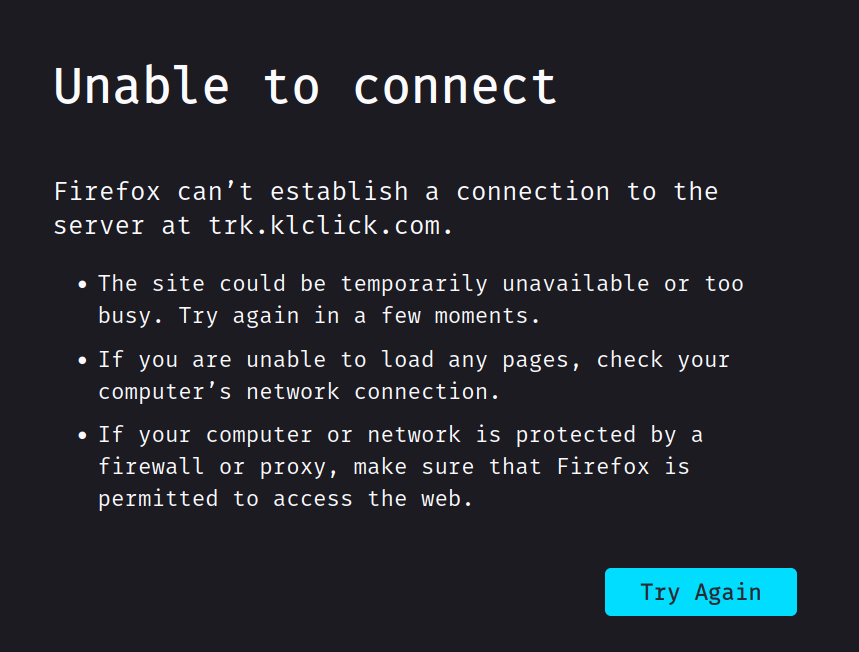
"Oh no," you might say, "it's an error message!" Something must be wrong.
Aha! Do not be deceived. This is indeed an error message, but this is exactly
what I wanted. See, on my home network if I ask for an IP address coming from
klclick.com, I get this result:
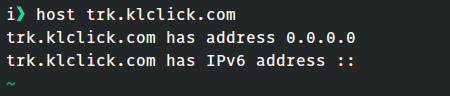
The address of 0.0.0.0 is technically a valid IP address, but it's a nonsense
address if you're trying to talk to somebody across the Internet.
If I ask for that address from somewhere other than my home network:
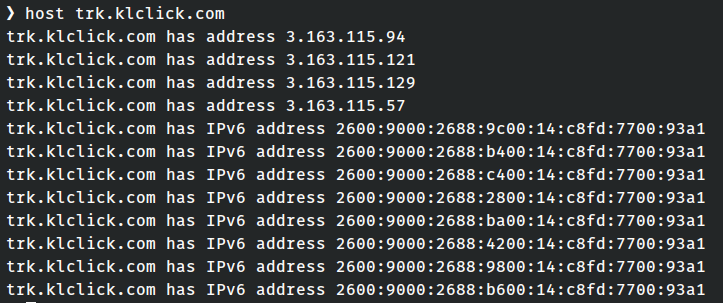
...I get something pretty drastically different, which is the actual result
(the actual IP address that responds for klclick.com).
So why is my home network returning a nonsense answer?
For this particular case, this is a feature and not a bug. On my home network, if something gets flagged as a 'tracking' site, a service called pihole will return this nonsense address when asked. It's a fairly effective way of blocking trackers and other potentially malicious actors that your devices might be asked to reach out to.
Buuuut... in this case, I still want to see what's on the other side of this
tracking link. I still want a friendly and rational discussion. So I temporarily
disable blocking for klclick.com for now.
I ask Firefox to refresh. And whups, tripping on yet another tripwire:
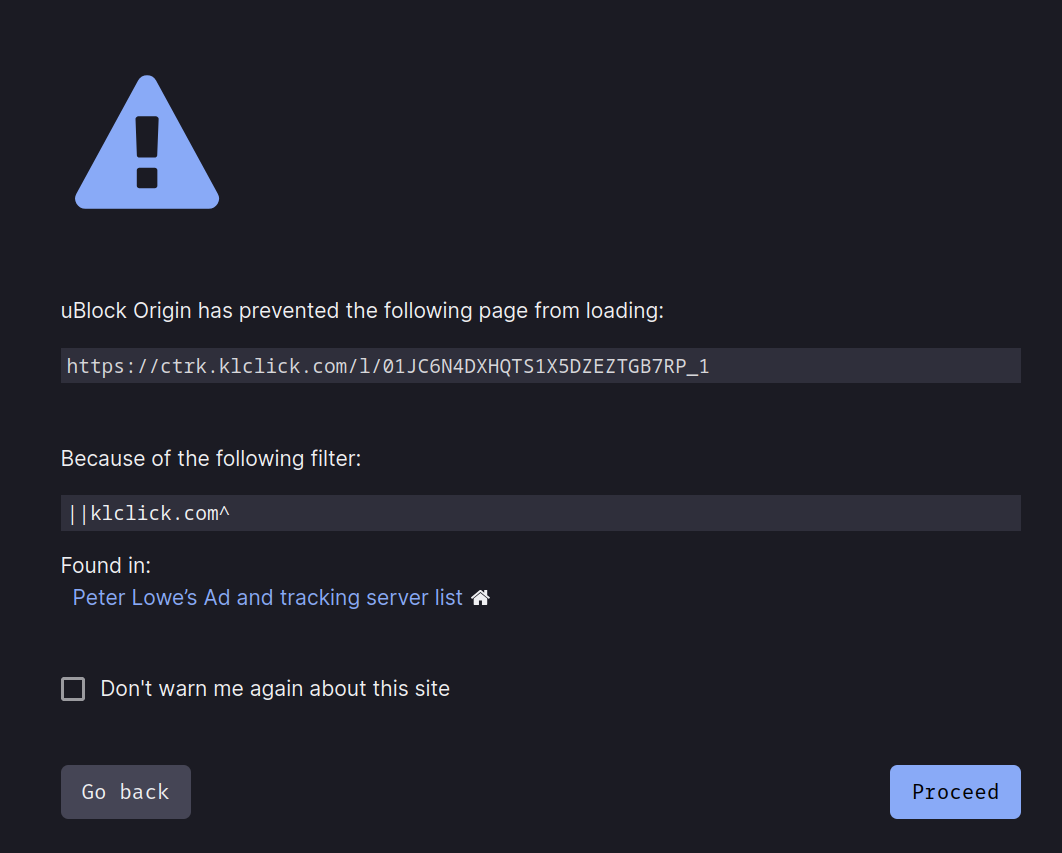
This one is also self-inflicted. As a second line of defense my uBlock Origin browser extension will also attempt to keep me from clicking on bad things. And it has (correctly) identified this link as an advertising and tracking service.
But, gosh darn it, I still want to hear the friendly and rational discussion
that was promised. So I click through with the [Proceed] button.
And finally, I get something that looks sort of like a podcast:
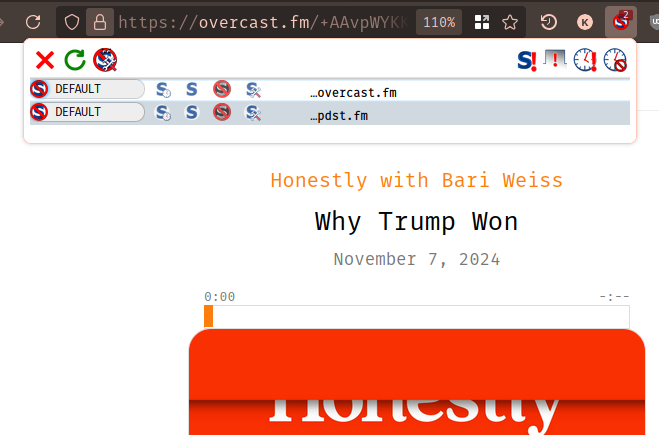
...only to see that yet another component is being blocked:

Because I am a glutton for punishment, I recognize this as the behavior of yet another security-minded browser extension, NoScript. Here we see the NoScript extension doing its job by blocking the loading of the podcast (by disabling Javascript, as foreshadowed by 'No' and the 'Script' in 'NoScript').
What does Javascript have to do with playing a podcast? Well, brief diversion, but...
Brief Diversion #
By default and by design, your web browser will load dozens of different files when transferring and displaying a web page. You clicking on a link is just the first step a long process. After your click, your browser will download some initial HTML document, but that will then trigger further downloads of images, styling information, and something else called Javascript.
Javascript (to be brief), is a programming language. It is the programming language that is used in web pages. And because of that, it is one of the most popular and ubiquitous programming languages on the planet. If you have loaded a web page in the last 30 years, you have likely run thousands of programs that somebody has written in Javascript.
However, we usually don't think of Javascript 'programs' in the same way we
think of others. A Javascript program isn't one that you run by double-clicking
on your desktop. There is no .exe file. No, most Javascript that you see is
tacked onto the end of a web page. Javascript (still trying to be brief) is
what separates a single, dumb web page of text and images from the more modern,
dynamic, and interactive experiences like Spotify or Google Sheets.
Javascript is powerful, and can do most anything that other programming languages can do. But most Javascript programs on the web are innocuous. They answer basic questions like, "what do I do if I click this button?" or "should I display this message box right now?" Real uninteresting stuff, but important if you want people to have a decent experience on your web page.
A key aspect of a Javscript program, though, is when it is run. By default and by design, any Javascript program that is included with a web page will be ran immediately after it downloads. This is to ensure that the user's experience is fast and is also exactly as the web page designers intended.
And, ominously, because Javascript is powerful, and because it can do most anything, that means you can of course have malicious, nay, nocuous Javascript programs. If you can wire up a button, you can have that button try to steal passwords and bank account information from you. Or you can skip the button entirely and just ask Javascript to use your computer to mine for somebody else's Bitcoin while your scroll through some doom for a while. The world is malicious Javascript's oyster.
But in my experience, the outwardly malicious stuff is rare. Unless you reguarly wander around the seedier side of the Internet, you're probably fine. And web browsers are getting better at sanitizing Javascript's abilities and keeping the bad people away from your computer.
But because this is 2024, and the world is what it is, it's not the outwardly malicious things that get you. No, instead it's the mildly shitty things that everyone knows are a problem but everyone has given up on trying to solve.
Let's take the Anchorage Daily News (ADN), my local newspaper:
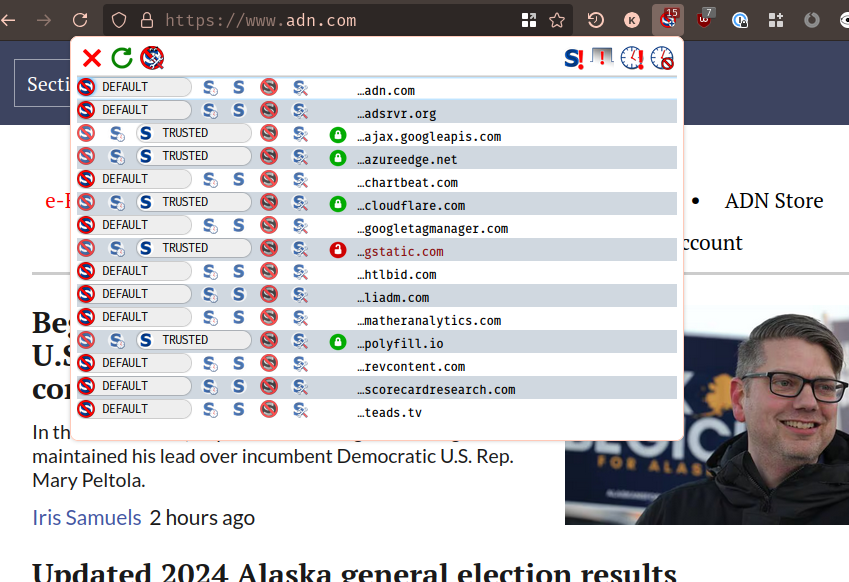
What are you seeing here?
Well, for every 1 page load of ADN, we have 14 other sites that ADN asks us to reach out to in order to load their front page.
Some of the items are legitimate. Some load Javascript programs used for the
display of the site, or load images and styling information. These are the ones
I have marked as TRUSTED (as otherwise the page doesn't load, or is just
unreadable).
But others are entirely for loading ads, or for loading Javascript programs that attempt to track my browsing activities. These are pretty easy to pick out of the lineup:
adsrvr.org(ads)chartbeat.com(tracking)googletagmanager.com(ads + tracking)matheranalytics.com(tracking)scorecardresearch.com(tracking)teads.tv(ads)
The others are less obvious, but if you search for them you'll see more of the same.
revcontent.com, search result describes it as a "Leading Content Discovery Platform for Advertisers & Publishers"

htlbid.com, no search results, but digging a little bit I'm pretty sure this is 'Hashtag Labs', another irritating publishing and monetization platform:

liadm.com, also no search results, but digging through the code that is being ran this is probably LiveIntent, yet another "one of the world’s largest people-based marketing platforms."

To be clear, I don't do this research for every site that I visit. Nobody has that kind of time.
I just wanted to show that (in this case) of the 14 external components for the website, there are 9 completely different advertising + marketing + browser tracking tools in play, each running their own Javascript programs.
For context: this is the situation for a local and sometimes struggling news outlet in a cold, dark corner of the world. They have fewer resources to dedicate to advertising and marketing than others, and so probably rely on third parties to help them with this. Maybe a number of external, specialized software vendors to manage their ads and who sees them. And why not, right? At the end of the day, they're a business. What's a few extra bytes across the wire, a few more milliseconds of processing time. Nobody will notice. Everyone needs to make a little money to keep the lights on. That's the dream, baby: monetization.
But for our own edification, maybe we should check some other similar web sites. Maybe it will be less annoying for CNN, a U.S. national news media outlet. Let's check:
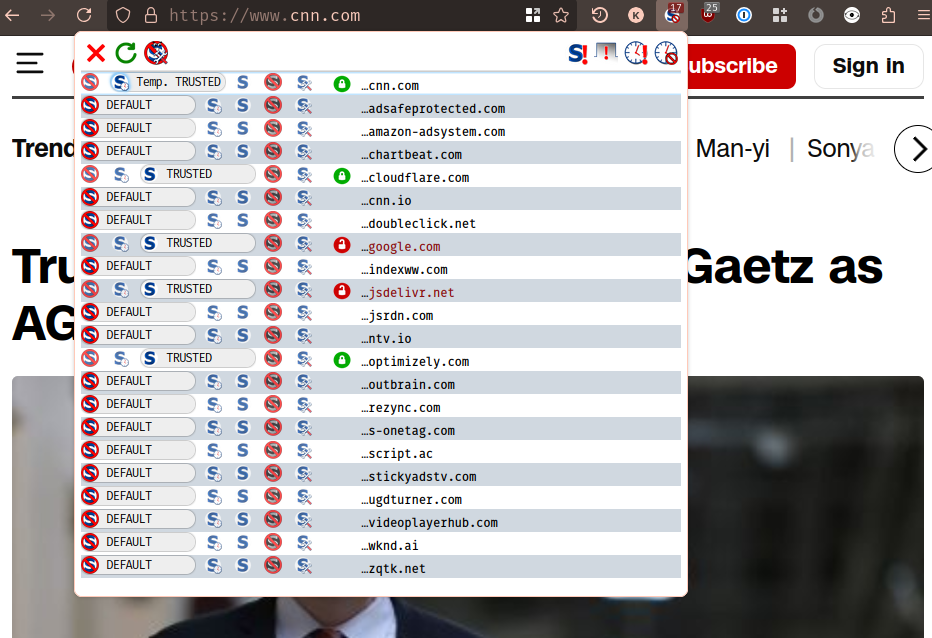
Nope. Just as many ads and tracking services. They also include a handful of references to external video media services, implying that in addition to serving ads they are also showing videos somewhere. And if you have been on any video platform in the last 10 years, you'll know: if you're watching a video on the Internet, you're probably going to see an ad along with that video.
Anyway. Let's try another. What about National Public Radio (NPR)?
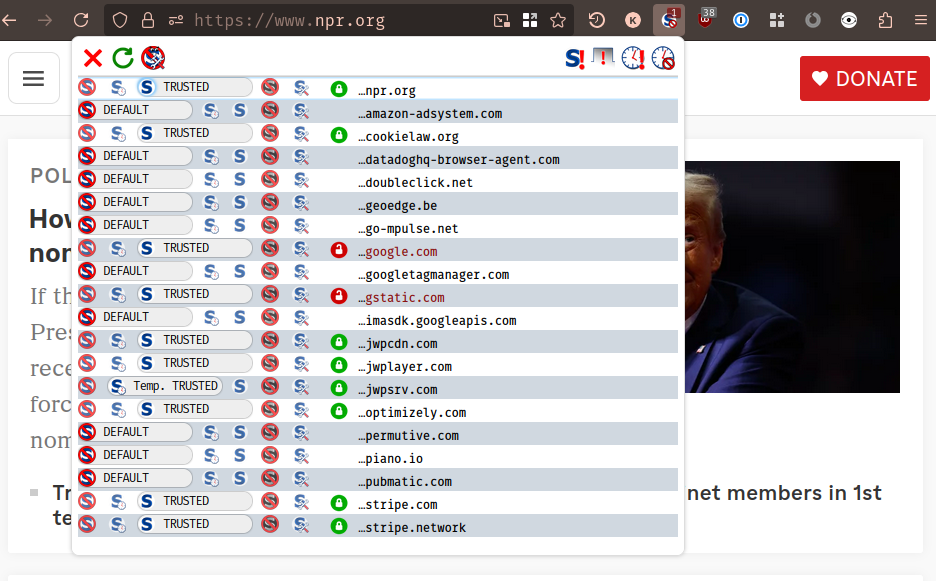
Fun. Just about as many, with some similar video services. They also include
references to Stripe, a popular payment processor. This is presumably what
powers the [❤️ Donate] button at top right.
Note that I have not donated to NPR (sorry), but the stripe.com and
stripe.network sites are marked as TRUSTED because I've had to use them
as an online payment processor in the past. So, for better or for worse, marking
Stripe as 'trusted' in my blocker has marked them as trusted across all websites
(and thus, enabling execution of Stripe's Javascript anywhere it happens to be
used). In other words, Stripe now knows that I view NPR, and NPR also knows that
I use Stripe. How fun.
In the perverse interest of being fair and balanced, what about Fox News?
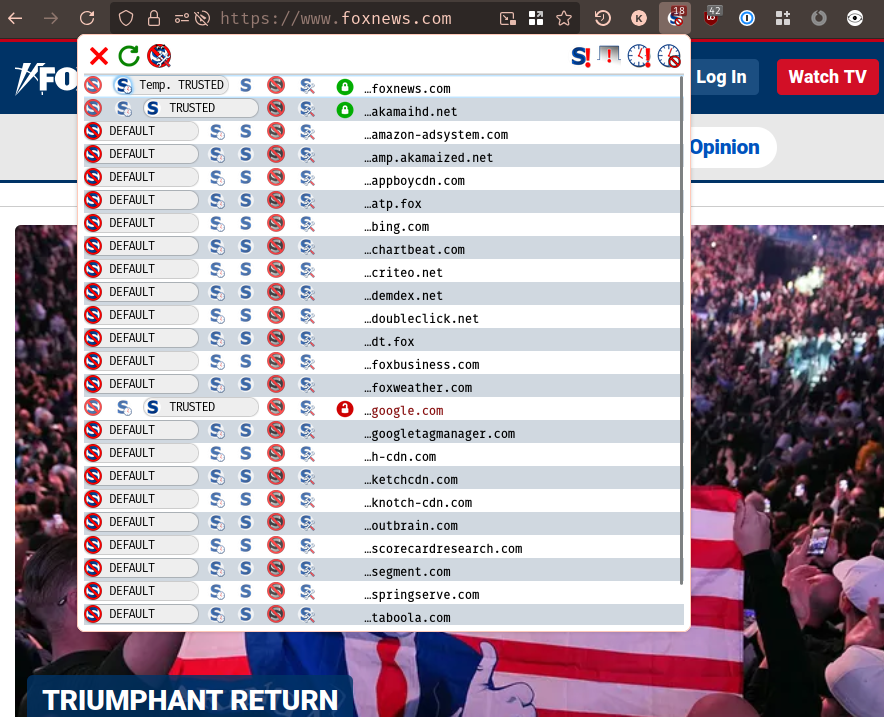
The same. I mean, I guess I respect the consistency. But not a whole lot.
Anyway. I think you see what I'm getting at. But before I do this for the rest of the Internet, let's pause. I'm not showing you all of this because I'm particularly fond of screenshotting news media sites and reminding you of what is on them. I'm also not showing you this because I think that this is a particularly new concept (mildly shitty people have been abusing web pages to sell ads and track people since there have been web pages).
I am showing you this to demonstrate the level of bullshit I'm used to dealing with on a day to day basis. Even after the DNS hacks and ad blockers, this "trust, don't trust" game is one that I play with just about every web site that I visit frequently. And this is exactly what that process looks like: an unending game of whack-a-mole, guessing what is actually required to load a web page and what is there just to load a tracker on my computer and tick a number on somebody's analytics dashboard.
It takes a lot of patience. And, frankly, sometimes you have to be an experienced software engineer to figure out what works and what doesn't. It's a frustrating, painful, and tedious process. But I still find it to be valuable. I copy my NoScript configs from computer to computer because I have so much invested in them, and because they're actually effective. It helps to reduce the number of ads I see, but also sticks a finger in the eye of somebody looking for a way to easily track what I'm interested in across the Internet.
It's also illuminating to see who is participating in this type of surveillance, and why.
What were we talking about? #
Which brings me back to the podcast I was trying to listen to.
After I click on the newsletter tracker, I get redirected to this URL:
https://overcast.fm/+AAvpWYKKZFM?_kx=ipVycftOsSm5LuYmUmB7wzr21iprn3EydNQ0ANp5dqROPTJ08EywgWdmlrgBViF7.VwvJFc
I recognize overcast.fm as a podcasting platform. At least we're in the right
place.
I start by 'trusting' the root domain name, overcast.fm, which is the site
that I'm visiting, but that doesn't load the podcast. Instead, it's showing that
there's a remaining MEDIA reference located at pdst.fm that NoScript is
blocking as well:
Okay, then what is pdst.fm? Googling around, it seems like it used to be a
podcast analytics platform (tracker) called 'Podsights' that was bought out by
Spotify.

The URL for the file that is being requested looks something like this (with some bits elided):
https://pdst.fm/e/mgln.ai/track/.../RSV5835768415.mp3
There's a lot going on there. We'll get back to this later, but at least there
is a reference to an .mp3 audio file at the end.
Admittedly, I don't know the ins and outs of how podcasts are published/distributed. If it's like anything on the Internet after a while, it's probably huge, over-complicated, and over-engineered.
What I do know is that every podcast episode has to be an audio file (.mp3,
.aac, etc.). And that large networks like Apple Podcasts, Spotify, etc., take
it upon themselves to host those podcast files on behalf of the podcast
creators.
For all I know, the above pdst.fm URL is just a common way that podcasts are
referenced and stored. The word 'track' doesn't always have to malicious,
doesn't always have to be a 'tracker' that's trying to surveil you across the
Internet. Albums have 'tracks,' right? Races have 'tracks.' Maybe everything is
okay, Josh, and you just need to move on. Maybe being a computer programmer is
knowing that you'll never get to the bottom of everything, and being able to
accept and commit to that fact is the only way you're going to lead a happy
life.
Either way, that pdst.fm URL looks like it could be the audio file I want.
I try to enable pdst.fm. But that only refreshes the page and updates the
media reference to something living at mgln.ai:
The mgln.ai site belongs to Magellan AI, yet another site that is "empowering
brands and publishers to scale podcasts and track outcomes better than their
competitors" (a tracking company):
So, the player that was loaded for the podcast is not simply loading the podcast media, but is forcing me to be directed through this publishing and tracking platform. Great.
But I think I still want a friendly and rational discussion in the form of a
podcast. So I hold my nose and temporarily allow mgln.ai to go through....
Same thing, just now we're dealing with something called podscribe.com:
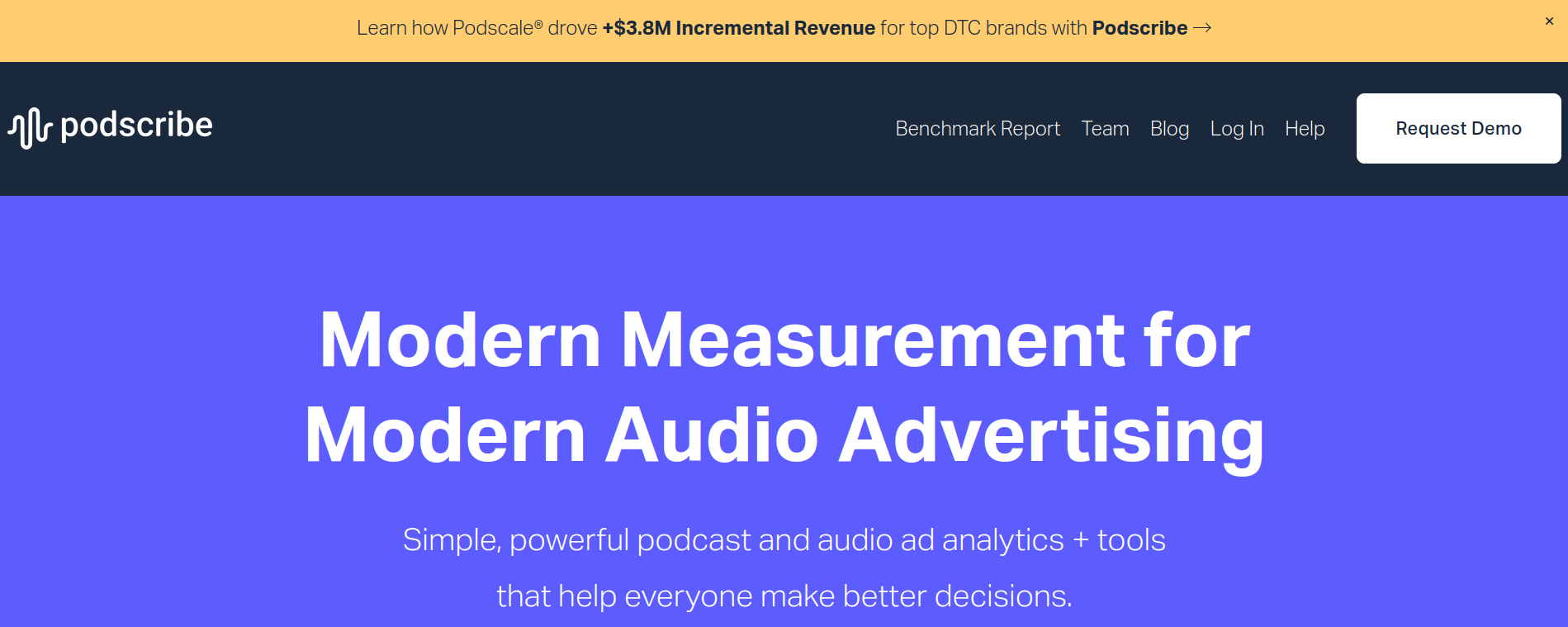
Getting frustrated. But surely we're almost through the pain. I temporarily
trust podscribe.com, and then..
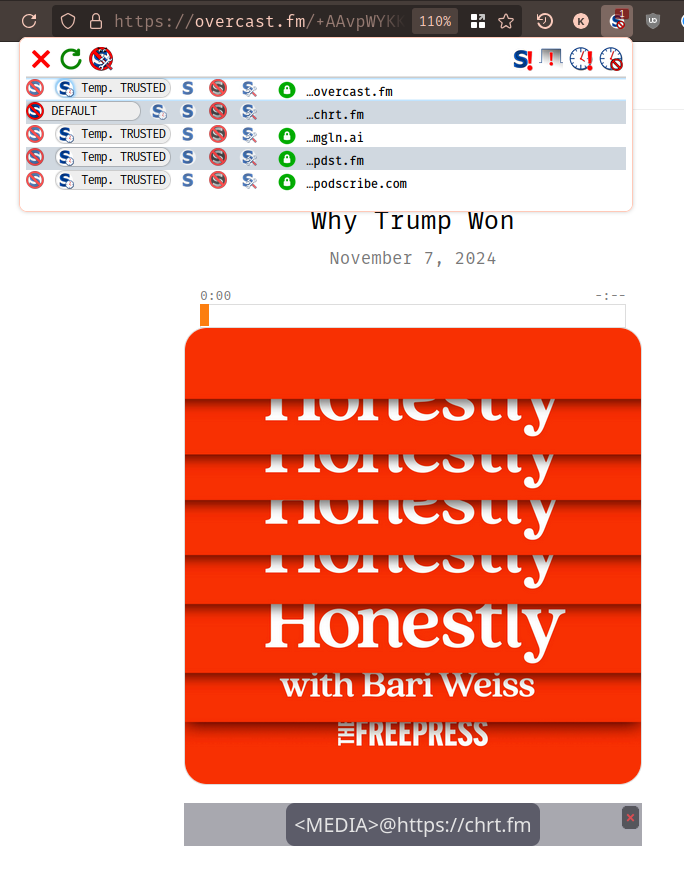
Googling around, chrt.fm belongs to Chartable, which looks like it used to be
another podcast analytics platform, but has been 'sunsetted'.

Let's roll them dice one more time. Temporarily trust chrt.fm, and what do we
get?
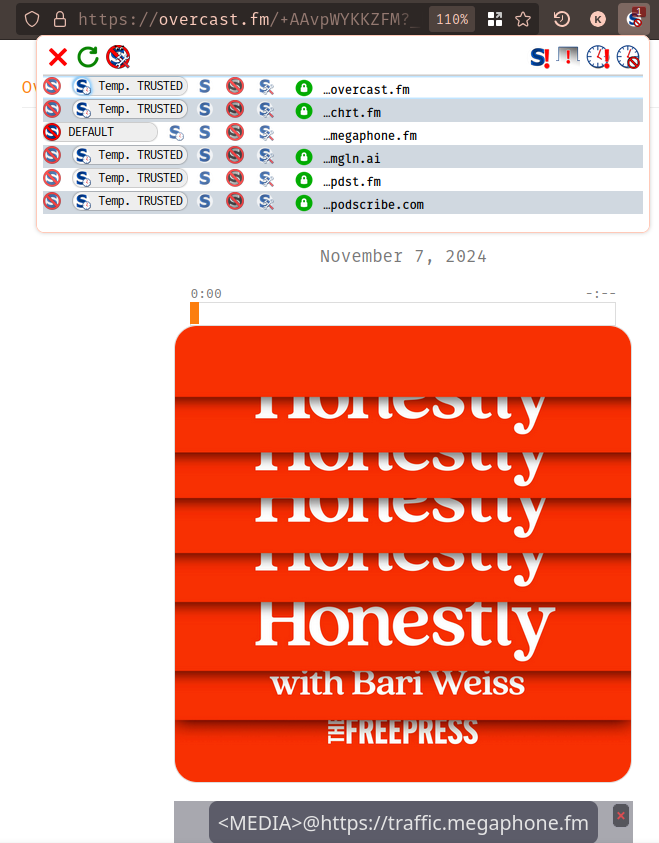
...Yet another media analytics/tracker!
At this point, I was a little curious. Why do we have 5 different tracking sites being loaded here? I looked at the traffic for the requests, and saw this:

Essentially, the site made one request for an .mp3 file at pdst.fm (but was
actually a tracking URL), which was redirected mgln.ai (but was actually a
tracking URL), which was redirected to podscribe.com (but was actually a
tracking URL), which was then redirected to chrt.fm (but was actually a
tracking URL), and then redirected to megaphone.fm (but was actually a
tracking URL), and then finally reached what was an actual .mp3 file for my
computer to download.
That's wading through 5 trackers in order to get through to a single media file.
After all this, the player widget finally loaded correctly and I was able to listen to a friendly and rational discussion. Actually, no. First, I had to listen to a 15 second ad for burgers, calling me to action by asking me to give in to my burger cravings. But then... then I finally got to start listening to what I wanted. As you can imagine, by then I was nowhere as interested as when I'd started.
If I'd left all of my ad blockers and tracking protections and mitigations in place, I wouldn't have been able to access this media at all. But now that I've turned off all of these tripwires and safety nets, I'm now exposed to the following tracking services:
-
klclick.com(the tracking URL set up via the newsletter authors, or by their newletter provider, Klaviyo, to indicate whether I clicked on their link to the fair and rational podcast) -
pdst.fm(the Podsights tracker, recording my media access for Spotify and its business partners) -
mgln.ai(the Magellan tracker) -
podscribe.com(the Podscribe tracker) -
chrt.fm(the Chartable tracker) -
megaphone.fm(the Megaphone tracker)
That's 6 trackers involved with trying to download a podcast episode. And that's probably ignoring a number of tracking mechanisms that I didn't catch. I'm sure when I clicked on the link in my email that Gmail logged it (for 'safety' reasons). I'm certain I haven't found all of the mildly shitty things going on during this process.
But that's the future we're living in.
It's at this point in my writing where I'm getting that feeling. That feeling of slightly higher air pressure where you know that you're losing someone's attention. That you've overstayed your welcome, physically and mentally. That feeling that somebody wants to look at their watch very badly. It's coming through the screen, through time and space.
I can feel it: you're asking yourself, "What of it?"
Why should you care about any of this? You've probably read articles in the Economist. You know that if you didn't pay for something (on the Internet), then you are the product. They want your eyeballs. They want your impressions. It doesn't matter if they're a news outlet or a podcast platform, the product is your attention. And somebody needs to be paid.
So anyway. I'll try to be a good steward of your attention. Here's the juice.
The thing that bothers me about all of the above is this initial URL (formatted for readability):
https://pdst.fm
/e/mgln.ai
/track/verifi.podscribe.com
/rss/p/chrt.fm
/track/384D27/pscrb.fm
/rss/p/traffic.megaphone.fm
/RSV5835768415.mp3?updated=1730955870
You probably noticed it already, but it took me a long while of staring.
Each of those redirects in that chain? The chain that sent you from tracker to tracker to tracker to tracker to tracker to tracker? They're all spelled out, in order, in that first URL that was loaded.
See, initially I thought all of those redirects was a result of buyouts, the wreckage of leftover computer systems that can't be given death with dignity. After all, when Spotify buys out Podsight, they can't just turn off all of Podsight's computers. What about all of the links still out there on the Internet that link to somewhere on Podsight? That's all ad traffic just waiting to happen when somebody maybe clicks on them again.
No problem, I might have said. Easy fix. When Spotify takes over Podsight's servers they just re-wire them to redirect to somewhere else. A barely noticeable delay, and nobody notices.
But that's an incomplete explanation. See, only pdst.fm (Podsight) and
chrt.fm (Chartable) were bought out or 'sunsetted'. The rest of the trackers
are still active (as far as their websites indicate).
Which made me think this is something else. Which made me stare at that URL for a long while.
If you capture all of the URLs in the redirect chain it takes to get us to the
.mp3 file, this is the progression you get:
https://pdst.fm/e/mgln.ai/track/verifi.podscribe.com/rss/p/chrt.fm/track/384D27/pscrb.fm/rss/p/traffic.megaphone.fm/RSV5835768415.mp3
https://mgln.ai/track/verifi.podscribe.com/rss/p/chrt.fm/track/384D27/pscrb.fm/rss/p/traffic.megaphone.fm/RSV5835768415.mp3
https://verifi.podscribe.com/rss/p/chrt.fm/track/384D27/pscrb.fm/rss/p/traffic.megaphone.fm/RSV5835768415.mp3
https://chrt.fm/track/384D27/traffic.megaphone.fm/RSV5835768415.mp3
https://traffic.megaphone.fm/RSV5835768415.mp3
https://dcs-spotify.megaphone.fm/RSV5835768415.mp3?...
Now look at them with my whitespace added and cleaning up the uninteresting bits:
https://pdst.fm/e/mgln.ai/track/verifi.podscribe.com/rss/p/chrt.fm/track/384D27/pscrb.fm/rss/p/traffic.megaphone.fm/RSV5835768415.mp3
https://mgln.ai/ track/verifi.podscribe.com/rss/p/chrt.fm/track/384D27/pscrb.fm/rss/p/traffic.megaphone.fm/RSV5835768415.mp3
https://verifi.podscribe.com/ rss/p/chrt.fm/track/384D27/pscrb.fm/rss/p/traffic.megaphone.fm/RSV5835768415.mp3
https://chrt.fm/ traffic.megaphone.fm/RSV5835768415.mp3
https://traffic.megaphone.fm/ RSV5835768415.mp3
https://dcs-spotify.megaphone.fm/ RSV5835768415.mp3
This is confusing, but I'll try to spell it out.
The first URL is a full description of a tracker chain. It starts with
mgln.ai, and ends with megaphone.fm. The idea is to describe all of the
trackers that need to be 'hit' during a request for RSV5835768415.mp3, and
that chain gets kicked off when the browser asks for the first, full pdst.fm
URL.
When pdst.fm receives its request, it tracks whatever it needs to track
internally, and then forms a new URL with the rest of the tracker chain, but
directed to mgln.ai (less the part with /mgln.ai). They do this by issuing
their own redirect with a new URL, but this time with the 'satisfied' part of
the chain snipped off.
Then when mgln.ai receives its own request, it snips off the
track/verifi.podscribe.com portion of the URL before redirecting over to
podscribe.com.
This happens for each of the steps in the chain until we reach the end, and our
computers finally download RSV5835768415.mp3 from dcs-spotify.megaphone.fm
(presumably, not a tracker, but an actual file server that actually has that
file).
This works way too well to be a happy technical accident resulting from buyout and forgotten computer systems. I would argue that this is an engineered system. This is multiple tracking companies, very well aware of each other, and each agreeing that if everybody participates in this redirect chain mechanism then everybody wins.
Well, they win. I don't win. I'm now in the database of 5 different podcast analytics companies that are highly interested in selling the fact that I'm interested in fair and rational podcasts immediately after a controversial election. Yikes.
Two questions here that I want to answer before I give away the mic:
-
Why are they doing it this way?
-
Why are they doing this at all?
Why are they doing it this way? #
The first question I think has an easy answer. And it has to do with the phenomenon I was showing with the news media ad serving stuff I showed above.
A feature of HTML is that if you request an HTML document (a web page), the HTML document is allowed to describe other secondary resources that it "needs", and force your web browser to make requests for those secondary resources. This sometimes gets hijacked to serve you ads (like the analytics, brand management, and marketing platforms that get referenced on the news sites).
However, there is no such mechanism when you request an .mp3 file. An .mp3
file stores audio information, and has no 'secondary' resources. So your browser
just asks for the file. And you get it, or you don't. At no point does your
browser inspect the contents of the .mp3 file to ask, "Is there some
secondary resource I need to play this file?" No. The .mp3 file is
self-contained, and has no external resources.
So, without that HTML matryoshka doll mechanism to hijack, they needed to get creative. And so I think this is why they engineered this bizarre redirect chain. Sure, the browser may not present a mechanism for serving ads like they do with HTML. But a request can be redirected. And it can be redirected quite a few times before the browser starts to call shenanigans and stops following the redirects.
It's with this chained redirect mechanism that one request for a podcast episode
can get a 'hit' across 5 different trackers even though we only requested a
single .mp3 file.
Why are they doing this at all? #
A podcast platform relies on ad revenue, much like any other media company. It needs to be able to present its potential ad buyers with a system that allows them to track what's going on, but also, to allow them to make as good of a choice as possible about whether to serve an ad to a podcast listener.
My theory is this: for every 'hop' in the chain, that particular tracker has the opportunity to 'bid' on an ad. They look at the incoming user and ask questions like, "Have we seen this person before?" and "Do we think there's an ad that is just right for them?" If a tracker decides no, then they just tally their counts and move on with their day. If a tracker decides yes, then they put up a bid for that ad slot (in a backend, hidden bidding system). If nobody outbids that tracker, then that tracker 'wins', and can have that hidden backend system automatically insert an ad into the beginning of my podcast listen.
So, when I heard a burger ad, somebody said, "Yeah, this guy needs a burger." And so they put up a bid and won the chance to play me a burger ad to ask whether I was ready to give in to my cravings.
They weren't wrong. But I'm happy to say that they wasted their bid.
What of it? #
At some indeterminate point in the last few years I started to hear a voice. That is to say: my voice, repeated back to me just a few seconds after I say something, almost like microphone feedback. Except it doesn't sound like a signal feeding back on itself. It just sounds like it's being passed through a "condescending technologist" filter. I hear what I sound like. I hear what I sound like to other people. I'm not a fan. I'm working on it.
In the meantime, I can't really stop with technology. But I can change my relationship with it.
I probably won't ever really understand the full breadth and depth of why the above podcast system works the way it is. I might be very off, and the weirdness I'm pointing out may be solving some problem I would never have considered. But I don't know. I've also been doing this for 20-some years now. This thing is weird. I might not be that off.
But I can at least tell you that this part of the system wasn't built for its listeners. And I can also tell you that the system would function just fine without it.
So my question for whoever built this: should you have built it in the first place?
- Previous: Do Not Forget